
Why cords aren't used in emacs and how they could be
Cords and emacs
What are cords?
You can think of cords as efficient strings. Specifically, "A number of operations on long cords are much more efficient than their strings.h counterpart. In particular, concatenation takes constant time independent of the length of the arguments." 1
Cords are sometimes called ropes, as in this implementation. Internally, they look something like this:
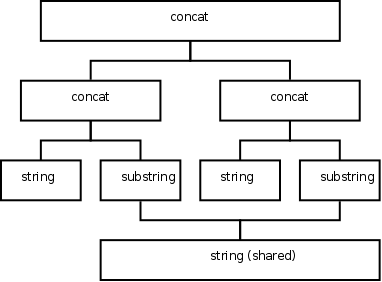
Why can't they be used for emacs?
Of course the first thought that occurs to any emacs-o-phile is, if it's so efficient, why isn't something like that used in emacs? There are editors that use cords; Hans Boehm wrote one to show off the power of cords.
But emacs makes heavier demands on its text representation than that little proof-of-concept editor. What's missing? What can't cords do that emacs needs? Off the top of my head, just these things:
- Text properties.
- Overlays, but I'll group them together with text properties.
- Markers
This got me thinking, and I decided to solve these problems, at least on paper. I'm sure of course that there are other problems lurking that I don't see.
Markers
Markers, for those not familiar with the inner workings of emacs, are like positions in a buffer except that they move with the text. They are not fixed numbers.
ISTM markers in cords could be implemented as a variant of the empty string node. Outside code would hold references to them. Since they must have an identity and be permanently empty, some shortcuts aren't possible.

This treatment of markers has side benefits:
- Markers automatically stay in their right position. There is no need to manage them when text elsewhere in the buffer in inserted or removed.
- Markers stay in their given order. That is, even if two markers are at the same position, one always comes first, and that order never changes. For a coder, this is a much better situation than trying to control markers that might be at the same location. 2
-
In theory, a marker could be garbage-collected when no outside code
knows about it. Since these markers don't have to be actively
managed (as above), markers that aren't known outside the cord tree
are only known by their parents.
Their parents could hold them by something akin to weak references. A finalization operation could replace a marker by an empty string node, which takes less space.
A few functions such as `buffer-has-markers-at' would disappear, but they are just used for marker housekeeping, so the need for them would disappear at the same time.
Setting markers
Setting markers becomes essentially the same as inserting text: At the appropriate point in the cord tree, concatenate the old subtree and a new object. But now the new object is a marker object.
Inserting text at markers
Inserting text at these special leaves is straightforward: The marker
is replaced by a concatenation of string and itself.
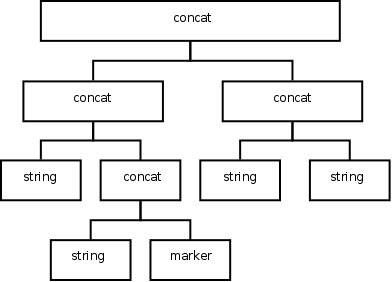
Savvy emacs users will immediately point out that that's one of two types of insertion operation. Emacs has another, as used for the marker insertion type `nil'. That just reverses the order: The marker is replaced by a concatenation of itself and string.
But with this it wouldn't make any sense to write:
(goto-char my-marker)
(insert "My text")
That would not distinguish markers. We'd be back in the old situation of managing marker-order by hand.
Instead, we'd like an insert-like operation that takes an explicit marker argument and acts with respect to it. Call it something like `insert*'. So you would write instead:
(insert* my-marker "My text")
Quick insertion
Now, that will work but it will make an awkward structure. If characters are inserted one-by-one, the tree will quickly degenerate into a list of single characters.

We don't want that. Plus we would like inserting at a marker to be as much like inserting at point as possible, and that has to be efficient.
So marker could have a variant expression as:
- (All its data described elsewhere)
- A fixed-size array of characters
-
A last-used position in that buffer
- In fact, two, because we can handle "before" and "after" insertions with the same buffer by letting it grow both from the top and from the bottom.
Small text insertions would go into that buffer. Later on when the small insertions had finished, the marker would be turned into a concatenation of marker and text. This would be done:
- When the little buffer was about to overflow.
- When a non-character is about to be inserted at it. Eg another marker or a "lazy" cord.
- When a marker was removed in garbage collection, being held only by weak references. Of course this would transform it into the text, not into an empty string as above.
- When the marker hadn't been used for insertion for a while.3
- When explicitly commanded to.
Point as a marker
The above would work reasonably well for point too, and for mark. But point has an additional requirement: It needs to can move around the buffer efficiently, ideally without changing the buffer cord at all.
So point cannot be just a marker. At least, it needs to also have a "phantom" aspect that can visually move around the buffer without really changing the buffer. This is essentially what emacs does under the hood now.
So ISTM point and mark must have these states:
-
"Numerical" state: It is associated to a numerical position.
When insertion or deletion is done anywhere in the buffer, point must not be in numerical state (otherwise it might get moved with respect to the text). So sometimes numerical state is automatically promoted to full position state.
-
"Full position" state: It is associated a position within a cord.
This is not susceptible to being moved by edits elsewhere.
-
"Marker" state: It is associated to a marker node, possibly one
created just for this purpose.
To insert or delete at point, point must be in marker state.
If the marker is removed (ie by killing text) marker state reverts to full position state.
Point vs the ordered-markers rule
(All the following discussion applies equally well to mark)
Point and mark also violate the ordered-markers rule. Since point moves around, it has no constant ordering wrt other markers.
I doubt that it makes sense to try to put point before or after certain markers based on what used to be markers' insertion type.
Instead we could do this:
- Normally place the new marker after any existing markers at that point.
- There'd be an alternative to place it before existing markers, along the lines of `insert-before-markers'.
- And for more fine-grained control, point could be associated to an existing marker. Perhaps when `goto-char' gets a marker argument.
But that doesn't work well. We said point had to switch from numerical state to full position state when an insertion (etc) occured anywhere in the buffer. So point might have invisibly, unpredictably already been placed before/after existing markers. That would make for erratic behavior.
So instead the before/after bit would be decided when point moves. It'd be something like:
- Numerical state includes a new flag, whether we are before/after markers. Defaults to "after".
- `goto-char' or a variant of it can explicitly set that before/after state.
- The transformation from numerical state to full position or marker state consults that flag.
- Again, there are operations to associate an existing marker to point for fine-grained control.
- What when a marker is inserted at point?
Now what happens when a marker is inserted at the same position as point? As before, we don't want to create an unpredictable situation and point may have invisibly gone into full position state. Is there a potential for point's placement to depend on whether this (invisibly) happens?
ISTM no. The situations are these:
- If the marker is normally inserted, point is effectively the marker argument to insert*. So point is already in marker state.
-
The marker is inserted at another marker. This can only create
ambiguity if the new marker is where point would go, ie either
after the last marker and point will go after markers, or the
symmetric situation before markers. Assume it's the first.
- Say marker M is inserted first, then point goes into full-position state. Point will go after M.
- Say point goes into full-position state first, then marker M is inserted. So marker M is inserted after another marker, which places it before point.
- So in either case, point goes after M.
- So in every case, there is no unpredictable behavior in this regard.
The kill ring
When text is copied or killed to the kill-ring, it'd usually be bad for later insertion at a marker to alter the string that's in the kill-ring. Even worse would be if the text was subsequently copied into another buffer and that completely unrelated buffer was surprisingly altered. This hazard applies not just when text is killed, but any time a string is gotten from a buffer, by buffer-substring, copy-region-as-kill etc.
Yet markers in bare strings might sometimes be useful:
- For moving active text from one buffer to another.
- For sharing active text among several buffers.
- For editing strings not attached to a buffer, especially when the editing operations are complex. One could generate a buffer just for the string and add appropriate markers, and this is generally what we do now. But it drags in the entire buffer mechanism just to edit a string.
My first idea, which was bad
My first idea to support this was to take a cue from Xemacs' extents and distinguish whether a marker is `duplicable'. `duplicable' markers could be captured in strings, others could not. A marker would always be `unique' in the Xemacs extent sense, and would default to non-duplicable.
Another approach
But I prefer another approach. It seems to me that the useful operations above all "want" to exert control over the copying operation itself. So we could distinguish different modes of buffer-string/buffer-substring operations:
- A mode that copies markers
- A mode that removes them from the copied text (pseudo-finalizing them along the lines described above)
- And possibly smarter modes that treat markers in a more fine-grained way according to the markers' properties.
Overlays, extents, and text properties
The problem
Overlays, extents, and text properties pose a different problem. Cords don't naturally have text properties. If we had to change the text of a cord to add properties to it, we'd lose much of the benefit of cords. So we want a way of annotating swathes of text without altering the text itself.
A solution for one is nearly a solution for all
Overlays, extents, and text properties are similar. AUIU Xemacs' treatment of them essentially merges them. There their predefined properties are the same, and the difference seems to be that an extent is itself an object to be held while text properties are part of a string or buffer. Since a solution for any one is basically a solution for all, I will focus on overlays.
First idea: A variant of substring node
My first idea was there would be a variant substring node that would have properties. Those properties would be interpreted as the properties of the subtree that it points to. Think of it as a substring node that "tints" the larger string or cord that it points to. I'm going to call it a PASS (property-adding substring node) for short.
Problems
But it has problems.
- The biggie: Cord substring nodes want edits to be made above the substring, not in its subtree. As soon as any edits are made, the simplicity of our scheme falls to pieces.
- Priority is capricious. It implies that for a PASS Early contained in a PASS Late, that Late always has higher priority than Early.
- This forbids crossed scopes. Usually they're not wanted, but sometimes they're needed, eg for transient mark mode.
-
Cord substrings want to point at constant text. But we need to can
place PASSs around arbitrary text, and that can be a cord.
This one may not be serious; we could simply loosen what we let substring nodes point to. They may not even need additional place information, since what's underneath them doesn't change and what's above them just uses their indexing as an offset.
Second idea: Explore to the text leaves
Exploration
We need to consider potentially many overlays at each position. So we need to look at every applicable PASS node. But that means that we may have to descend pretty far down the tree to get all the properties that might be in force. We can explore more efficiently than that.
Worse, it doesn't work. We usually encounter a string before we encounter the PASS node that it was added on top of.
Handles crossed scopes
Once multiple priorities can be accepted, crossed scopes are handled naturally by this scheme. Nothing forces a PASS to refer only to a subtree that is entirely scoped beneath it, and subtrees can be shared.
Third idea: Other nodes link to PASSes
So we can't do all that we need with PASS nodes. But we want properties to behave like a contiguous stretch of text, and PASS has the advantage that it really is contiguous stretch of text. So I'll mostly base my plan on PASS nodes.
So let's use:
- PASS nodes
-
String nodes that also have:
- a pointer to a PASS node
- an index into it (used to explore deeper)
-
Markers that have (in addition to what I wrote above):
- Pointer and index to a PASS node before it
- Pointer and index to a PASS node after it (possibly the same as the before node)
Editing operations keep them in sync. Usually strings point to the PASS node below it that was applicable when it was created.

To explore PASS nodes
PASS nodes themselves can't keep a single PASS pointer, or even a fixed number. They might contain arbitrarily many sub-regions with different properties. So when dealing with them, we adjust the index and explore that position recursively.
Shortcut
We can make some optimizations:
We can let PASS node pointers be null, and treat such as an indication that nothing underneath has properties.
Also, each PASS node could indicate whether there is any higher priority PASS underneath it. If not, we could examine it and only descend further if it failed to provide what we seek.
Inserting vanilla text
Generally when we insert text, we want the text to inherit properties from it. Now, this is not what emacs does now. Its behavior is actually inconsistent: single characters inherit text properties from around them, inserted strings do not. IMO it is cleaner and more convenient to let all insertions (by default) inherit text properties from around them. The plan above does that.
But sometimes we really want to insert text with new properties or no properties. We can do this by either:
- (for the vanilla case) Setting a null PASS pointer or
- (For the non-vanilla case) Over the whole insertion, placing a PASS node that indicates that there is no higher priority PASS underneath it.
Kill ring
What happens when a PASS is copied into the kill ring? Much like with markers, we probably want to support variant copies:
- Remove all properties. We could replace PASSs with vanilla substrings but it's probably simpler to place a "shortcut" PASS over the whole thing.
- Keep properties. Ie, do nothing special. This can cause duplication in different buffers.
- Treat PASSs individually depending on `duplicable' and `unique' properties, as borrowed from XEmacs.
How to be overlays
In this scheme, an overlay is just a PASS that something outside the cord refers to.
Conclusion
So it seems to me cords are feasible in emacs. I can confidently say that the obvious design problems can be solved. But as I said earlier, I'm sure of course that there are other problems lurking that I don't see.
Footnotes:
1 From cord.h by Hans Boehm
2 I have done some coding with ewoc and to extend ewoc. For this, I don't recommend trying to control which of several markers comes first at all. It can be done, but it's a royal mess. Instead, I recommend removing all markers that are only separated by empty text and adding them just when they will be separated by non-empty text. But that's just a work-around. The fix would be for markers to automatically stay in their respective order.
3 This makes me wonder if it would be worthwhile to have "mess compaction", in analogy to garbage collection. Instead of removing and finalizing an object, "mess compaction" would transform it into a more compact form, idiosyncratically by object type. More on this later.
No comments:
Post a Comment