Mutability And Signals 3
Now
So recently I've been looking at how that might be done. Which basically means by fully persistent data structures. Other major requirements:
- Cheap deep-copy
- Support a mutate-in-place strategy (which I'd default to, though I'd also default to immutable nodes)
- Means to propagate signals upwards in the overall digraph (ie, propagate in its transpose)
Fully persistent data promises much
- As mentioned, signals formally replacing mutability.
- Easily keep functions that shouldn't mutate objects outside themselves from doing so, even in the presence of keyed dynamic variables. For instance, type predicates.
- From the above, cleanly support typed slots and similar.
- Trivial undo.
- Real Functional Reactive Programming in a Scheme. Implementations like Cell and FrTime are interesting but "bolted on" to languages that disagree with them. Flapjax certainly caught my interest but it's different (behavior based).
- I'm tempted to implement logic programming and even constraint handling on top of it. Persistence does some major heavy lifting for those, though we'd have to distinguish "immutable", "mutate-in-place", and "constrain-only" versions.
- If constraint handling works, that basically gives us partial evaluation.
- And I'm tempted to implement Software Transactional Memory on it. Once you have fully persistent versioning, STM just looks like merging versions if they haven't collided or applying a failure continuation if they have. Detecting in a fine-grained way whether they have is the remaining challenge.
DSST: Great but yikes
So for fully persistent data structures, I read the Driscoll, Sarnak, Sleator and Tarjan paper (and others, but only DSST gave me the details). On the one hand, it basically gave me what I needed to impelement this, if in fact I do. On the other hand, there were a number of "yikes!" moments.
The first was discovering that their solution did not apply to
arbitrary digraphs, but to digraphs with a constant upper bound p on
the number of incoming pointers. So the O(1) cost they reported is
misleading. p "doesn't count" because it's a constant, but really
we do want in-degree to be arbitrarily large, so it does count. I
don't think it will be a big deal because the typical node in-degree
is small in every code I've seen, even in some relentlessly
self-referring monstrosities that I expect are the high-water mark for
this.
Second yikes was a gap between the version-numbering means they refer to (Dietz et al) and their actual needs for version-numbering. Dietz et al just tell how to efficiently renumber a list when there's no room to insert a new number.
Figured that out: I have to use a level of indirection for the real indexes. Everything (version data and persistent data structure) hold indirect indexes and looks up the real index when it needs it. The version-renumbering strategy is not crucial.
Third: Mutation boxes. DSST know about them, provide space for them, but then when they talk about the algorithm, totally ignore them. That would make the description much more complex, they explain. Yes, true, it would. But the reader is left staring at a gratuitously costly operation instead.
But I don't want to sound like I'm down on them. Their use of version-numbering was indispensable. Once I read and understood that, the whole thing suddenly seemed practical.
Deep copy
But that still didn't implement a cheap deep copy on top of mutate-in-place. You could freeze a copy of the whole digraph, everywhere, but then you couldn't both that and a newer copy in a single structure. Either you'd see two copies of version A or two copies of version B, but never A and B.
Mixing versions tends to call up thoughts of confluent persistence, but IIUC this is a completely different thing. Confluent persistence IIUC tries to merge versions for you, which limits its generality. That would be like (say) finding every item that was in some database either today or Jan 1; that's different.
What I need is to hold multiple versions of the same structure at the same time, otherwise deep-copy is going to be very misleading.
So I'd introduce "version-mapping" nodes, transparent single-child nodes that, when they are1 accessed as one version, their child is explored as if a different version. Explore by one path, it's version A, by another it's version B.
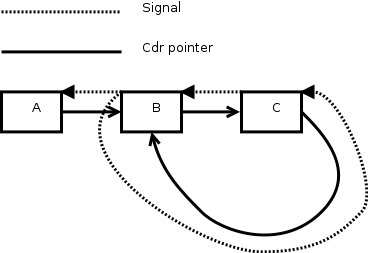
Signals
Surprisingly, one part of what I needed for signals just fell out of DSST: parent pointers, kept up to date.
Aside from that, I'd:
- Have signal receiver nodes. Constructed with a combiner and an arbitrary data object, it evaluates that combiner when anything below it is mutated, taking old copy, new copy, receiver object, and path. This argobject looks very different under the hood. Old and new copy are recovered from the receiver object plus version stamps; it's almost free.
- When signals cross the mappers I added above, change the version stamps they hold. This is actually trivial.
- As an optimization, so we wouldn't be sending signals when there's no possible receiver, I'd flag parent pointers as to whether anything above them wants a signal.
Change of project
If I code this, and that's a big if, it will likely be a different project than Klink, my Kernel interpreter, though I'll borrow code from it.
- It's such a major change that it hardly seems right to call it a Kernel interpreter.
- With experience, there are any number of things I'd do differently. So if I restart, it'll be in C++ with fairly heavy use of templates and inheritance.
- It's also an excuse to use EMSIP.
Footnotes:
1 Yes, I believe in using resumptive pronouns when it makes a sentence flow better.